
Transformer
理解一样东西需要细节数学运算和宏观意义把控,缺一不可
理论的理解和实践的熟练也缺一不可
相关学习资料
论文原文:
Attention is all you need
transformer代码实现:
Whole code
李沐
hugging-face:
encoder & decoder
论文写作
相关工作写清楚论文中用到的知识,哪些是前人已有的工作,哪些是作为自己的创新和不同而提出的
论文本质上是给别人介绍自己的工作,想一下如果论文火了能不能成为经典
ai之所以是玄学是因为,关键在于根据loss来反向传播更新权重,但是当参数量很大的时候,权重的具体表现,权重的改变对整个模型带来的影响,包括对数据有很多可行的处理方式,都是无法直观的理解不同设计的意义,以及不同改变带来的结果是怎么样的,都只能做事后诸葛亮
并不是每一步都有显著的意义,太不美了,不如数学,比如为啥要除的是 $\sqrt{d_t}$而不是$d_t$,
Transformer 架构理解
总架构如图(摘自论文):
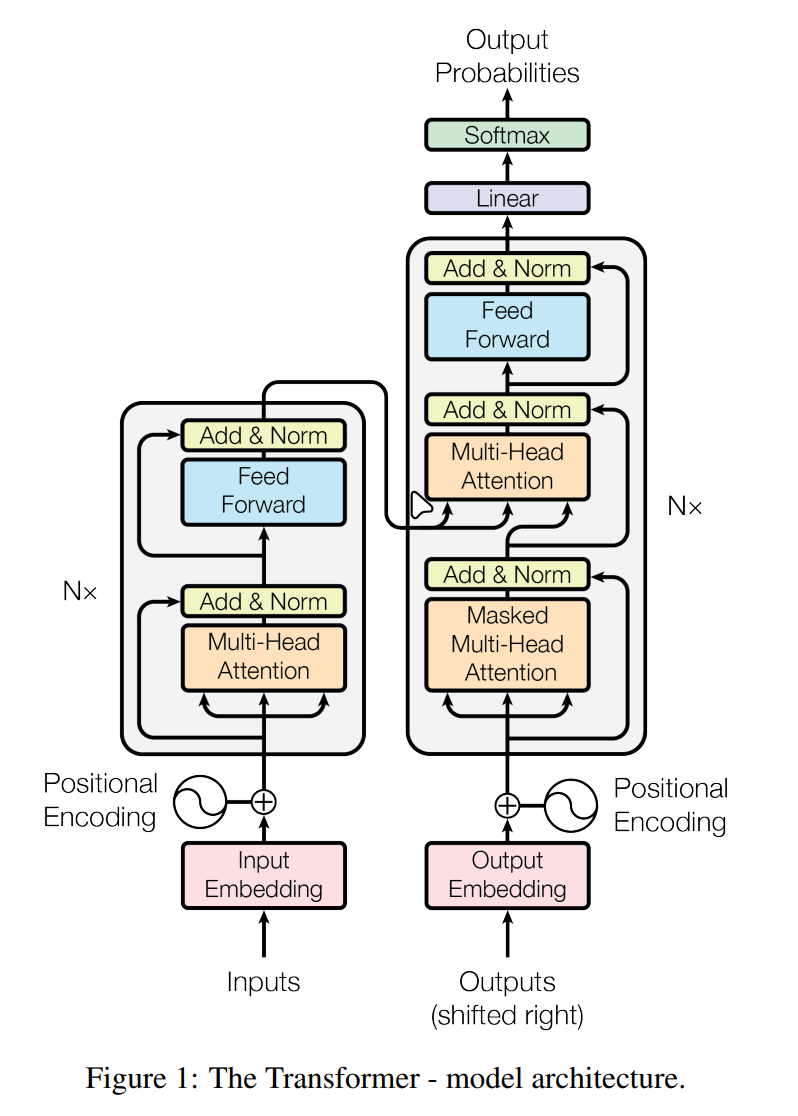
概述
总的来说,transformer是一个seq2seq的序列转录模型,主体有encoder和decoder两个部分:
- encoder接收原始输入,对输入进行一系列处理以后产生编码输出,传递给decoder
- decoder接收整体的encoder的输出和上一个decoder的输出(预测阶段)或者整个的目标序列(训练阶段),来生成对下一个token的预测
地位
在transformer之前,NLP使用RNN来预测,但是RNN需要之前的时间步作为下一个时间步的输入传递,速度慢,并且无法获取全局的信息
Transformer提出了全部基于注意力机制时间序列预测模型,意味着训练阶段不需要等待上一个时间步的信息输入,每次参数调整都是基于全局,直接获取全局信息,只有预测阶段的推理需要用到时间步循环
从抽象上来看,tranformer将每个具有不同上下文环境的输入token映射到了一个超高维的空间中,来记录不同上下文环境的token的位置,并在预测阶段进行拟合
这种做法像是把上下文信息(或者现实世界的其他格式信息)也作为了数据的一部分进行具象化,来以很多参数记录
为什么其他模型没有transformer这么具有统治性的地位?其设计思想背后的精髓之处是什么?
存疑,缺乏宏观视野
具体架构
根据图片能看出,总体是常见的翻译模型的架构,有两部分,编码器和解码器,编码器接收原始输入,解码器接收编码器输出和目标序列的输入或者已经预测的目标序列(见后面详解)
编码器负责将输入的序列首先转换成向量的形式(映射到向量空间),然后通过注意力机制来调整向量学习输入向量全局的信息,再通过前馈层来扩展特征信息,输出具有输入全局上下文的输入向量
解码器较为复杂,解码器接收的输入有两部分,一部分是编码器输出的原始序列向量,另一部分(Outputs)是:
- 训练阶段:整个目标序列的输入
- 预测阶段:之前生成的所有token
最终的输出是: - 训练阶段:对于给出的目标序列中,对于每一个词的下一个词的预测概率(经过softmax之后的logist),输出整个预测的序列,并和给定的正确的目标序列做损失函数来调整参数
- 预测阶段:经过softmax生成一个预测单词,并加入下一个时间步的token的decoder输入中
训练阶段:
预测阶段: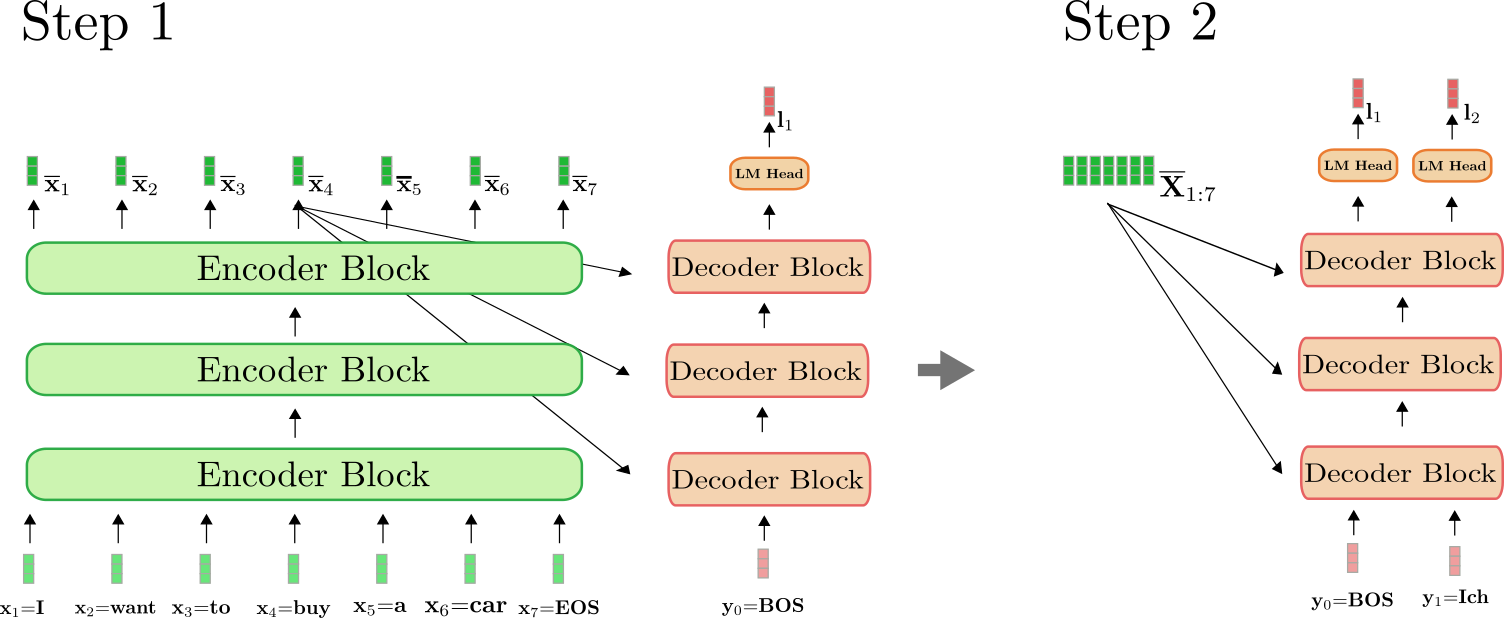
以上是对整个transformer的输入和输出的介绍,下面详解编码器和解码器的详细架构
首先分别介绍几个模块
Embedding
embedding层是One-hot的替代,使用低维稠密的one-hot矩阵进行计算更快速。embedding会使用Word2vec训练出一个词嵌入矩阵,每一个词对应一个词向量,将句子中的词使用one-hot编码,再与词嵌入矩阵相乘,即可有词矩阵,词向量转化在二维空间中,可以代表不同词之间的含义的关系
在transformer中,embedding词向量的维度是512,并且在embedding之后还要数值的扩大,因为embedding编码之后因为有L2正则化,所以输入维度越大,每个向量的值越小,所以transformer乘了一个$\sqrt{512}$来扩大,来能够匹配position encoding的大小
Position Encoding
对于输入的词向量,由于注意力机制关注的是整个序列的所有token的相互之间的影响,但是我们希望的是前一个token对后一个token的预测,所以序列中token的顺序也至关重要,所以对于输入的embedding向量,还要进行position encoding编码来标明每个token的位置信息
具体的标注方式如下:
其中的$pos$是token的位置,$d_{model}$是512,通过计算正余弦来生成一个尺寸也是512的向量,并与embedding向量相加,获得带有位置编码的向量
那么问题来了,为什么仅仅是相加就能让模型识别到向量的位置信息,模型如何辨别向量的值是position encoding相加得来,还是原本的值?
答:这tm是玄学
代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=1024, **kwargs):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
positional_encoding = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).float().unsqueeze(1)
# 位置编码的缩放因子
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
(-torch.log(torch.Tensor([10000])) / d_model)) # [max_len / 2]
positional_encoding[:, 0::2] = torch.sin(position* div_term)
positional_encoding[:, 1::2] = torch.cos(position* div_term)
# 传入参数形状为[seq_len, batchsize, embedding_size(d_model)]
positional_encoding = positional_encoding.unsqueeze(0).transpose(0, 1)
# 注册缓冲区来持久性保存位置编码
self.register_buffer('pe', positional_encoding)
def forward(self, x):
# x即为传入的序列向量,只加到x的序列长度
x = x + self.pe[:x.size(0), ...]
return self.dropout(x)
注意力机制
从输入输出上看,注意力机制实现了更新输入向量来达到记录向量之间的关系
从含义上看,注意力机制设计的目的是根据输入的所有向量来找到每一个向量之间的关系,所以输入是要使用注意力机制的向量,输出是对向量进行相互之间的注意力更新,产生上下文来存储信息
为什么transformer要使用注意力机制?
因为注意力机制能关注到全局信息,并且不需要上一个时间步的输出,同时更新所有信息,其底层的运算就是简单的矩阵运算,所以可高度并行
缩放点积注意力(Scaled Dot Product Attention)
总的注意力机制公式为:
基本缩放点积的注意力机制如下: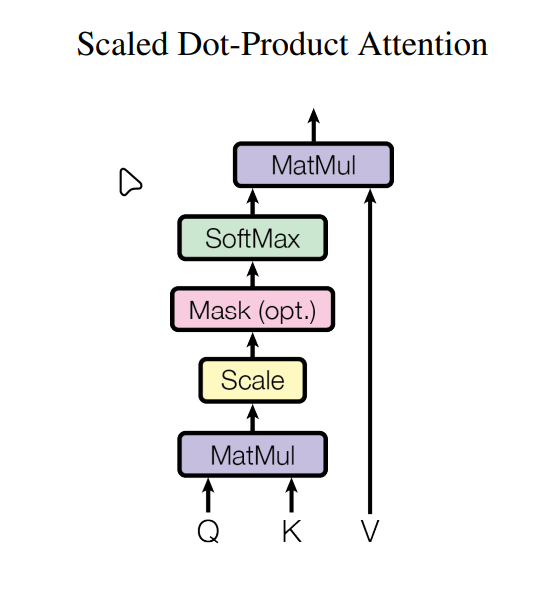
注意力机制中有三个矩阵:Q,K,V
其中Q为query,K为key,V为value
对于特定的查询,寻找和键值之间的相似度,计算出相似度矩阵,并加权乘V矩阵,然后以此来更新向量(相加,表现为残差),在查询之后使用softmax来讲注意力权重归一化
Q的维度比嵌入向量小很多,意义是映射到一个带有查询含义的更小的空间,所以寻找相似度的方法是,Q与K的乘积越大,代表越相似
而缩放点积指的是在计算出相似度权重矩阵$QK^T$之后,为了防止过大的值导致梯度更新困难,所以除以一个$\sqrt{d_k}$来缩小点积结果
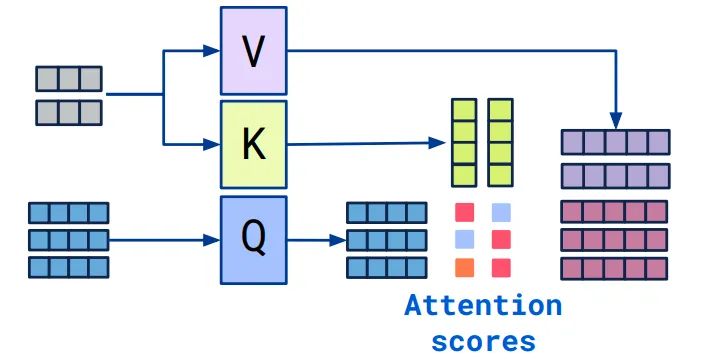
其中V的尺寸很大(和嵌入矩阵维度一样),所以进行大矩阵的低秩分解,分解成$d_q(d_v) * embedding_size$大小(以及转置大小)的矩阵,来减少参数
每一个单头注意力有唯一一个$w_q, w_k, w_v$
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 缩放点积注意力
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, atten_mask):
'''
Q: [batch, n_heads, len_q, d_k]
K: [batch, n_heads, len_k, d_k]
V: [batch, n_heads, len_v, d_v]
attn_mask: [batch, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
# 什么掩码?
scores.masked_fill_(atten_mask, -1e9)
# 对于每个查询(Query),计算其与所有键(Key)的相似度分布。
# 获取相似度矩阵attn和增值向量prob
attn = nn.Softmax(dim=-1)(scores) # [batch, n_heads, len_q, len_k]
prob = torch.matmul(attn, V) # [batch, n_heads, len_q, d_v]
return prob, attn
自注意力(Self-attention)
transformer中使用的是自注意力机制,即输入的Q,K,V是同一个矩阵——输入向量,意义是注意力更新的是输入向量本身
有三个注意力权重$w_q, w_k, w_v$与输入向量相乘
自注意力是Q,K,V是同一个矩阵X,X做一定线性变换$w_q, w_k, w_v$来作为Q,K,V矩阵,来更新自己
不同的注意力是根据Q,K计算权重矩阵的的方式不同
多头注意力
为了向CNN的多个过滤器一样提取一个序列中的多种注意力机制,所以使用多重注意力,每个头有一个自己的$w_q, w_k, w_v$,其中$w_v$很特殊,多头中只有一个子矩阵(待进一步研究),
muti-head attention相当于卷积网络的多层输出,每一层提取不一样的特征,transformer中投影了h次,投影到低维再最后把所有结果加回来
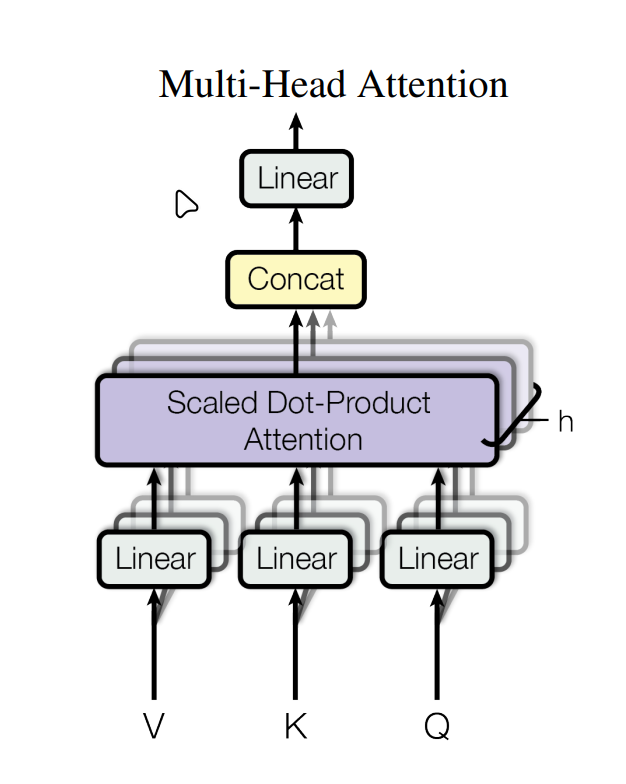
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47class MultiHeadAttention(nn.Module):
# 多头需要原始的残差给到Norm层
def __init__(self, n_heads=8):
super(MultiHeadAttention, self).__init__()
self.n_heads = n_heads
self.attention = ScaledDotProductAttention()
# 整体权重矩阵
self.W_Q = nn.Linear(d_model, d_model, bias=False)
self.W_K = nn.Linear(d_model, d_model, bias=False)
self.W_V = nn.Linear(d_model, d_model, bias=False)
self.W_O = nn.Linear(d_model, d_model, bias=False)
self.layer_norm = AddNorm(d_model)
def forward(self, input_Q, input_K, input_V, atten_mask):
'''
To make sure multihead attention can be used both in encoder and decoder,
we use Q, K, V respectively.
input_Q: [batch, len_q, d_model]
input_K: [batch, len_k, d_model]
input_V: [batch, len_v, d_model]
输入的是原始的总维度
'''
residual, batch = input_Q, input_Q.size(0)
# if atten_mask.dim() == 2:
# atten_mask = atten_mask.unsqueeze(1).unsqueeze(2) # (batch_size, 1, seq_len)
# print(f"atten_mask shape before repeat: {atten_mask.shape}")
# 将乘积结果切分为多头
Q = self.W_Q(input_Q).view(batch, -1, n_heads, d_k).transpose(1, 2) # [batch, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch, -1, n_heads, d_k).transpose(1, 2) # [batch, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch, -1, n_heads, d_v).transpose(1, 2) # [batch, n_heads, len_v, d_v]
# 和attn匹配
atten_mask = atten_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# 传入缩放点积
prob, attn = self.attention(Q,K,V,atten_mask)
# 匹配总输入尺度,transpose后如果接permute或者view必须要加contiguous
prob = prob.transpose(1, 2).contiguous() # [batch, len_q, n_heads, d_v]
prob = prob.view(batch, -1, n_heads * d_v).contiguous() # [batch, len_q, n_heads * d_v]
# 包括输入与输入的微调,其中output就是微调的结果
output = self.W_O(prob)
return self.layer_norm(residual, output), attn
Transformer中的注意力
transformer使用多头自注意力,在decoder中,首先目标(预测)序列经过一个带有mask的多头自注意力,然后输出作为Q,encoder的输入作为V和K,来更新预测向量
Mask
在transformer中有两种mask,一种是对于序列长度不一致的padding,要使用mask来将无意义的padding去掉,一种是对于decoder的注意力机制,在更新目标序列或预测序列的向量时要使用mask来让后面的token不影响前面的token的向量更新,因为后面token对于前面token应该是未知的
对于padding_mask,有两种使用场景
- encoder_input和decoder_input需要mask
- encoder_Input和decoder_input之间需要mask
首先是对于输入向量的基本padding:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def make_data(sentences, max_length):
encoder_inputs, decoder_inputs, decoder_outputs = [], [], []
for i in range(len(sentences)):
# 获得index序列
print(sentences)
encoder_input = [source_vocab[word] for word in sentences[i][0].split()]
decoder_input = [target_vocab[word] for word in sentences[i][1].split()]
decoder_output = [target_vocab[word] for word in sentences[i][2].split()]
# Pad encoder_input
encoder_input += [0] * (max_length - len(encoder_input))
encoder_input = encoder_input[:max_length] # Truncate if longer
# Pad decoder_input
decoder_input += [0] * (max_length - len(decoder_input))
decoder_input = decoder_input[:max_length] # Truncate if longer
# Pad decoder_output
decoder_output += [0] * (max_length - len(decoder_output))
decoder_output = decoder_output[:max_length] # Truncate if longer
encoder_inputs.append(encoder_input) # [seq_index1, seq_index2]
decoder_inputs.append(decoder_input)
decoder_outputs.append(decoder_output)
return torch.LongTensor(encoder_inputs), torch.LongTensor(decoder_inputs), torch.LongTensor(decoder_outputs)
padding_mask:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 生成padding掩码,大小和相似度矩阵相同
def get_attn_pad_mask(seq_q, seq_k):
'''
Padding, because of unequal in source_len and target_len.
parameters:
seq_q: [batch, seq_len]
seq_k: [batch, seq_len]
return:
mask: [batch, len_q, len_k]
'''
# 两个seq_len的长度是不同的,# 注意使用残差连接
class AddNorm(nn.Module):
def __init__(self, norm_size = d_model, **kwargs):
super(AddNorm,self).__init__()
self.dropout = nn.Dropout(p=p_drop)
self.layer_norm = nn.LayerNorm(norm_size)
def forward(self, x, y):
return self.layer_norm(self.dropout(y) + x)
batch, len_q = seq_q.size()
batch, len_k = seq_k.size()
print(len_q, len_k)
# we define index of PAD is 0, if tensor equals (zero) PAD tokens
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch, 1, len_k]
return pad_attn_mask.expand(batch, len_q, len_k) # [batch, len_q, len_k]
attention_mask:1
2
3
4
5def get_attn_subsequent_mask(seq):
atten_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequent_mask = np.triu(np.ones(atten_shape), k=1)
subsequent_mask = torch.from_numpy(subsequent_mask)
return subsequent_mask
Norm
batchnorm: 在一个batch的样本里面,将所有样本的同一个特征(列)变为均值为0,方差为1
layernorm:对每一个样本做normlization,而不是feature
MLP
MLP:单隐藏层,从512维度扩展到2048再到512
1 | class FeedForwardNetwork(nn.Module): |
attention之后的向量中已经包含了序列信息,所以直接对每个词向量单独做MLP就可以
MLP的作用是将序列信息映射成更为复杂的语义空间,加大拟合的程度,有更多参数
全流程
encoder:
encoder输入做embedding编码,以及position编码,投入到N=6的layer中,每一层经过一个自注意力和一个MLP,最后获得总的encoder输出
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# 重复的layer
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self._self_mutihead_attention = MultiHeadAttention(n_heads)
self.norm = AddNorm(d_model)
self.ffn = FeedForwardNetwork()
def forward(self, x, pad_mask):
# x: [batch_size, seq_len, embedding_size]
x, attn= self._self_mutihead_attention(x, x, x, pad_mask)
x = self.ffn(x)
return x, attn
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(source_vocab_size, d_model)
self.position_encoding = PositionalEncoding(d_model=d_model)
self.layers = nn.ModuleList([EncoderLayer() for layer in range(n_layers)])
def forward(self, x):
input = x
x = self.embedding(x)
x = self.position_encoding(x.transpose(0, 1)).transpose(0, 1)
pad_mask = get_attn_pad_mask(input, input)
encoder_self_attns = list()
for layer in self.layers:
# encoder_output: [batch, source_len, d_model]
# encoder_self_attn: [batch, n_heads, source_len, source_len]
x, encoder_self_attn = layer(x, pad_mask)
encoder_self_attns.append(encoder_self_attn)
return x, encoder_self_attns
decoder:
训练阶段,输入目标序列,进行embedding和position编码,输入N=6的layer中,每一层经过掩码自注意力,与encoder一起的注意力,以及MLP获得输出,再经过线性层和Softmax获得每一个词之后的词的预测,根据目标序列来计算损失,反向传播,特性是每一次的预测词只与上一个的token有关
预测阶段也是一样,只是每次预测一个词,并加入到序列中参与下一个时间步的attention
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.mutihead_attention = MultiHeadAttention()
self.ffn = FeedForwardNetwork()
def forward(self, x, encoder_output, encoder_decoder_mask, self_mask):
x, decoder_self_attn = self.mutihead_attention(x, x, x, encoder_decoder_mask)
x, decoder_encoder_attn = self.mutihead_attention(encoder_output, encoder_output, x, self_mask)
x = self.ffn(x)
return x, decoder_self_attn, decoder_encoder_attn
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(target_vocab_size, d_model)
self.position_encoding = PositionalEncoding(d_model=d_model)
self.layers = nn.ModuleList([DecoderLayer() for layer in range(n_layers)])
def forward(self, decoder_input, encoder_input, encoder_output):
decoder_output = self.embedding(decoder_input)
decoder_output = self.position_encoding(decoder_output.transpose(0, 1)).transpose(0, 1)
# 有decoder自己的mask,包括pad和seq,也有pad类型的encoder_decoder_mask
# 和Encoder相对应, 但Decoder和Encoder使用了两个不同的Embedding. 对于Mask, 可以把自回归Mask和Padding Mask用torch.gt整合成一个Mask, 送入其中.
decoder_pad_mask = get_attn_pad_mask(decoder_input, decoder_input).to(device)
decoder_seq_mask = get_attn_subsequent_mask(decoder_input).to(device)
decoder_self_mask = torch.gt(decoder_pad_mask + decoder_seq_mask, 0)
encoder_decoder_pad_mask = get_attn_pad_mask(decoder_input, encoder_input).to(device)
print(f"encoder_decoder_pad_mask shape: {encoder_decoder_pad_mask.shape}")
decoder_self_attns = list()
decoder_encoder_attns = list()
for layer in self.layers:
decoder_output, decoder_self_attn, decoder_encoder_attn = layer(
decoder_output,
encoder_output,
encoder_decoder_pad_mask,
decoder_self_mask
)
decoder_encoder_attns.append(decoder_encoder_attn)
decoder_self_attns.append(decoder_self_attn)
return decoder_output, decoder_self_attns, decoder_encoder_attns
整体的transformer代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.fc = nn.Linear(d_model, target_vocab_size, bias=False)
# 不用softmax
def forward(self, encoder_input, decoder_input):
encoder_output, encoder_attns = self.encoder(encoder_input)
decoder_output, decoder_self_attns, decoder_encoder_attns = self.decoder(decoder_input, encoder_input, encoder_output)
outputs_logist = self.fc(decoder_output)
return outputs_logist.view(-1, outputs_logist.size(-1)), encoder_attns, decoder_self_attns, decoder_encoder_attns
