
BadPart
意义和提出
- 第一个对于大分辨率图像的统一黑盒对抗性补丁,即黑盒对于逐像素回归模型生成对抗性补丁
- 使用了方形区域划分优化(Square-based adversarial patch optimization)的随机噪声生成,然后进行概率采样和梯度分数优化生成噪声
原理
期望效果
显著降低黑盒逐像素模型(例如提供API的在线服务)性能
数学推导
总公式:
其中:
- h为高,w为宽
- $\mathbf{p}$ 是大小为3,h,h的噪声
- $p_0$是纯黑噪声(基准补丁)
- $[\mathbf{x}’_n] = \Lambda([\mathbf{x}’_n],p,q)$是在q处将p附加给图片x
- $\mathcal{F}()$是计算两个模型修改结果的逐像素误差,并使其最大化
输出:n,d,H,W的图片,The output of model M has a dimension of n × d × H × W , where d refers to the output channels for each image. For MDE models d equals 1 as the output is the estimated distance for each pixel, and for OFE models d equals 2 since the model outputs the estimated pixel-wise offset vector (two dimensions)
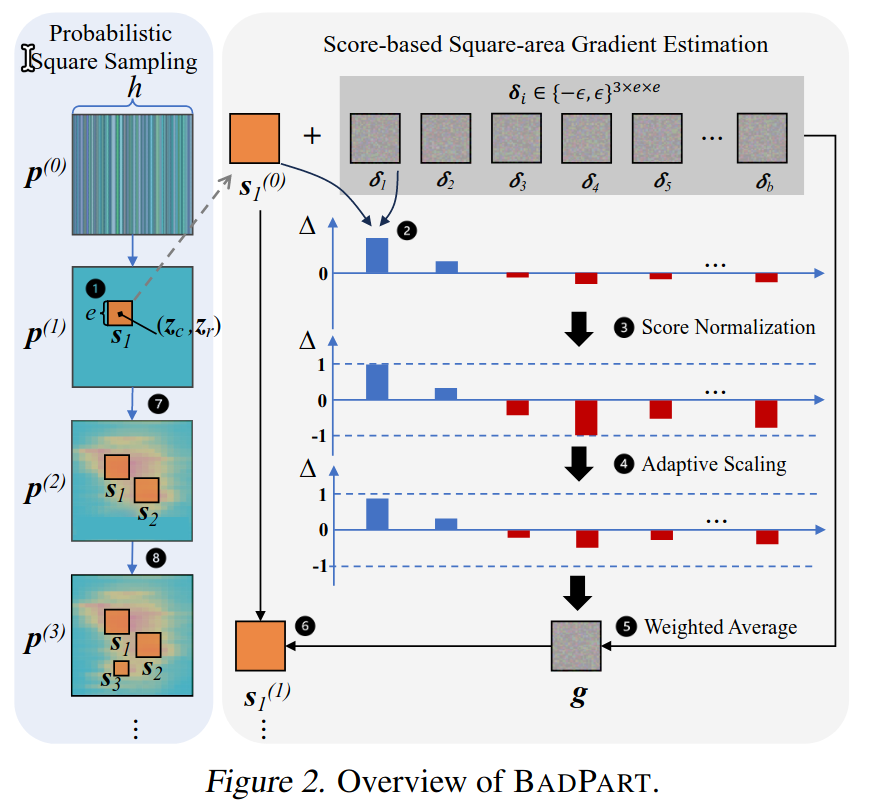
Probabilistic Square Sampling

The sampling algorithm is designed to enhance the probability of selecting locations within the patch region that are more vulnerable to adversarial perturbations.
选取由最新的补丁图片计算出来的逐像素误差图M,来展现出来的误差最大的区域,产生每个区域的采样的概率,所以称为概率采样
需要有迭代输入的原因是采样的尺寸是由关于迭代次数的预定义计划中获得的SizeSche(iter)
采样过程:
- 根据预定义计划来获取采样的大小,包含由粗到细的颗粒度,以及均匀采样阶段
- 平滑逐像素误差图M
- softmax获取概率
Score-based Gradient Estimation

该方法通过在局部区域生成并评估随机噪声,快速估计对抗性梯度,无需像传统零阶优化那样逐像素估计。这种方法有效提升了梯度估计的效率,同时能保持优化过程的稳定性。
传统方法(如零阶优化):
- 对每个像素分别生成扰动,计算其对损失函数的影响,逐像素估计梯度。
- 缺点:计算量巨大,尤其在高分辨率图像上,优化效率较低。
**本方法:
- 以方形区域为单位:在局部区域内生成随机噪声,整体评估其对攻击效果的影响,从而估计区域梯度。
- 提高效率:通过利用区域噪声的整体性,避免逐像素计算,显著降低了计算复杂度。
流程
局部区域确定:
- 确定一个正方形区域,作为梯度估计的范围。
- 区域位置由中心点 $(z_c, z_r)$ 和边长 e 决定,确保梯度估计集中于攻击关键区域。
随机生成噪声 $[\delta]_b$ :
- 在正方形区域内生成 b 组随机噪声 $\delta$,每组噪声的值限制在 ${-\varepsilon, \varepsilon}$。
- 每个像素的值为 $-\varepsilon $或$\varepsilon$ ,原因如下:
- 稀疏性假设:文献(Moon et al., 2019)指出,最优对抗噪声常位于约束空间的顶点,即取值为极端值($\pm\varepsilon$)。
- 生成的 b 组噪声有助于在约束范围内探索攻击效果。
计算加噪图片的评分 $[\Delta]_b$:
- 将每组噪声加到方形区域后,生成对应的加噪图片集 $[\hat{x}]_b$ 。
- 计算每张图片的评分(噪声对攻击效果的影响):
- $\hat{x}_i$ :加入第 ii 组噪声后的图片。
- $x’$:当前噪声优化状态下的基准图片。
- $F_e$:像素级误差函数,计算对抗噪声引起的预测误差。
- $\Delta_i$ 的正负含义:
- 正值:噪声提升了攻击性能。
- 负值:噪声削弱了攻击性能。
归一化评分 $[\Delta]_b$:
- 对正评分和负评分分别归一化,限制在 [0, 1] 和 [0, -1]:
- 按正负评分数量进一步缩放:
- 目的:
平衡正负评分的贡献,避免正负评分数量不对称导致优化方向偏差。
估计梯度 g:
- 利用归一化评分作为权重,对随机噪声进行加权平均,计算梯度:$\sum_{i=1}^b \Delta_i \cdot \delta_i$
- g 表示当前区域的梯度估计,指引噪声优化的方向。
L2归一化梯度:
- 对梯度 g 进行 L2 归一化,以控制更新幅度和方向稳定性:
更新当前噪声 s:
- 将估计的梯度 添加到当前噪声 s 上:
- 其中,$\alpha$ 为学习率,控制噪声更新的步长。
流程图
总框架:
算法:

基于竖条纹的随机噪声
迭代更新最大损失值
使用概率平方采样GETSQUAREAREA(iter, M, q, h)来获取更新的正方形区域
选取原训练图像上的方形图像区域,计算梯度来更新噪声正方形区域,直到最大损失不再增大
不断选取噪声方形区域,直到更新噪声不再使最大损失增大
代码实现
相关知识
“adversarial robustness” 机器学习模型在面对对抗性攻击(adversarial attacks)时,保持其预测准确性和稳定性的能力
搞清楚哪些是要花功夫去深入理解的,哪些不需要
感觉黑盒的对抗性模型在思路上也不复杂,只是需要的算力更高,因为需要迭代来寻找优化的方向,以及每一次迭代需要跑原模型进行验证
目前的黑盒攻击:
基于替代模型的攻击:
attackers construct a substitute model to execute white-box attacks and transfer the generated adversarial example to attack the victim model . To construct the substitute model, attackers employ the same training set as the victim model or reverse-engineer/synthesize a similar dataset.基于查询的攻击:
- hard-label attacks:Hard-label attacks assume that the attacker can only access the predicted label of the victim model
- soft-label attacks:soft-label attacks assume the prediction score of each class is available
对查询攻击的噪声优化方法:
- gradient estimation
- heuristic random search
- genetic algorithms
写作
“Meanwhile, on the other hand, the adversarial patch for online services could also act as a deterrent against unauthorized users who attempt to upload our photographs to those services for video composition” (Cheng 等, 2024, p. 2) 对于版权的保护也是一个意义方面,所以讲故事的时候要考虑其社会价值和意义
Question
1.为什么要计算基准补丁和对抗补丁之间的误差,而不是直接计算原始图片和对抗补丁之间的误差?
因为补丁的引入本身可能会干扰模型识别的结果,所以引入基准补丁来作为判准
