
Attack as Defense
意义和提出
传统的模型编辑是编辑作为推理的结果,所以传统后门的效果是当进行模型编辑的时候,后台给模型加一个后门标识,产生指定的更改结果
本文的模型编辑后台加一个mask noise,来保护指定的区域,在推理阶段不能根据text更改
并且使用的是原模型,只在推理阶段进行添加noise就可以达到保护的效果,所以称为运行时
利用的是后门可以指定激活一些神经元的特性,所以可以通过激活指定神经元来达到保护指定的区域的效果,同时保证其他区域的编辑和生成不受影响,确实很像后门
三个优化目标:
- 植入损失,
- 不完全触发损失,保持保护区域的激活
- 隐藏损失,保证编辑区域的可用性
三方:
- 模型商
- 用户
- 图片版权拥有者
很简单的思路:给定模型,对抗模型,训练noise来干扰功能,具体的idea是针对什么模型作出干扰,考虑两方面:
- 模型的选择,根据有没有实际的应用价值,以及前人有没有做过相关工作
- 没有工作就老方法解决新问题,探索新的模型的安全问题,Attack as Defense属于这个
- 有工作就新方法解决老问题,使用新的对抗或者优化方法,BadPart属于这个
原理
期望效果
训练出一个产生noise的模型,对于给定的mask和图片,可以生成对抗性的noise,能有效对抗给定的模型,也算是一个黑盒方法
数学推导
原始的后门模型
修复损失(inpainting loss):
- 原始图像和生成图像的像素差异$L_{inpaint}$
- 生成器的损失$L_{adv}$
其中的inpaint损失改为具有后门监督的损失,可以训练出具有后门的修复模型
Run-time backdoor
基于现有模型,不需要训练阶段的后门植入
其中:
- $\mathcal{P}(x)=x\otimes\mathcal{P}$ P是可训练的受保护区域的参数(?模型中的表现是什么:原始图片上加了一个可训练的随机噪声noise)
- $\phi_x$是target
- $\mathcal{IM}(\mathcal{P}(x),\mathcal{T}(m))$是加了扰动的保护图片
- $m_0$是除了保护区域之外的区域掩码
有加一个扩展掩码,因为实验结果表明只有部分区域能够收到保护,所以需要向外扩展一圈
更改后的公式:
其中,
- 扩展区域掩码为$\mathcal{E}(m)$
- 不属于原有的掩码但是属于现有掩码的部分为$\mathcal{E}’(m)$
总损失:
经实验证明,设置超参:
- hide的权重为2
- noise的迭代训练次数为20
简而言之就是给了两个优化目标,一个是保护区域,指标是能够加了保护噪音,一个是未保护区域保持原有功能
流程图
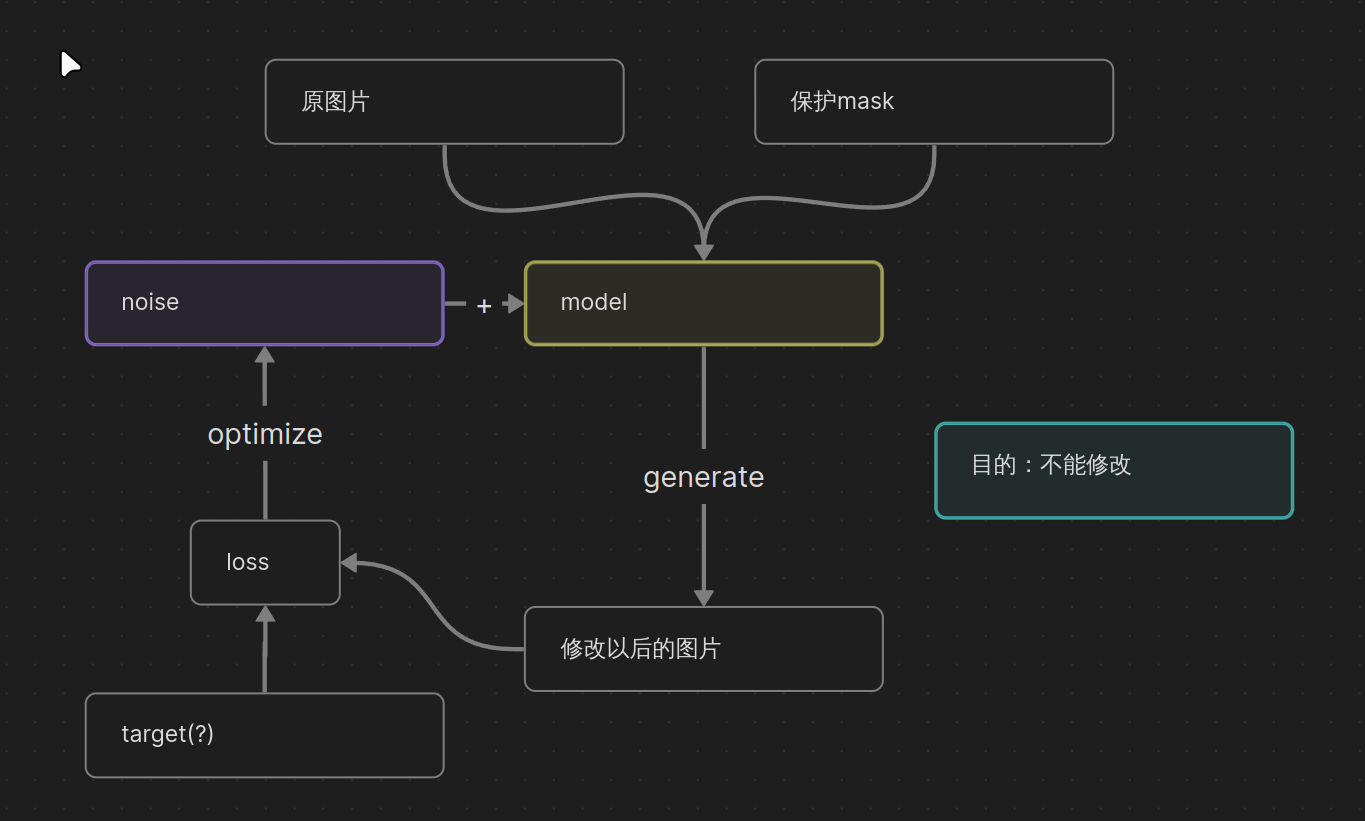
整体过程:对于给定的模型,根据原始图片和修改的mask,计算模型修改加了noise以后的修改结果和target之间的均方误差,然后更新noise来达到对抗修改的效果
代码实现:
$\phi_x$:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34# target是颜色为和原始图像中的平均颜色差别最大的颜色,尺寸为noise的目标图片
target = generate_target(ori_fname, (adv_noise.shape[3],adv_noise.shape[2])).to("cuda")
# 创建一个新的颜色为find_color_with_max_difference的图像
def generate_target(image, size):
img = PIL.Image.open(image)
width, height = img.size
max_diff_color = find_color_with_max_difference(img)
new_img = PIL.Image.new('RGB', (width, height), max_diff_color).resize(size)
new_img = preprocess(new_img)
return new_img
# 和图像平均颜色差异最大的颜色
def find_color_with_max_difference(img):
pixels = np.array(img)
average_color = np.mean(pixels, axis=(0, 1))
average_color = tuple(average_color.astype(int))
unique_colors = [(0,255,0),(255,0,0),(0,0,255)]
random.seed(42)
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# for _ in range(4):
# color = tuple(np.random.randint(0, 256, 3))
# unique_colors.append(color)
differences = [np.sum((np.abs(np.array(average_color) - np.array(color))/255)**2) for color in unique_colors]
max_diff_index = np.argmax(differences)
max_diff_color = unique_colors[max_diff_index]
return max_diff_color
扩展掩码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def expand_mask(mask_tensor, exp_size):
assert len(mask_tensor.shape) == 4 and mask_tensor.shape[0] == 1 and mask_tensor.shape[1] == 1, \
"the shape of mask has to be: 1x1xheightxwidth"
kernel = torch.ones(1, 1, exp_size, exp_size, dtype=torch.float32, device=mask_tensor.device)
padding_size = (exp_size - 1) // 2 #大小不变
expanded_mask = F.conv2d(mask_tensor.float(), kernel, padding=padding_size)
expanded_mask = (expanded_mask > 0).float()
return expanded_mask
'''main'''
expd_mask = expand_mask(batch_ben['mask'], 17)
batch_adv_expd['mask'] = expd_mask.to("cuda")
$\mathcal{E}’(m)$(barch_adv_hide):1
2
3
4batch_adv_hide['mask'] = batch_adv_expd['mask'] - batch_ben['mask']
batch_adv_hide['mask'].data = torch.clip(batch_adv_hide['mask'].data, 0, 1)
batch_adv_hide['mask'] = (batch_adv_hide['mask'] > 0) * 1
batch_ben_hide['mask'].data = batch_adv_hide['mask'].data
超参,hide的权重为2,noise的迭代训练次数为20:1
2
3
4#
loss = loss_attack + loss_incp + 2*loss_hide
# the number of training iterations for the protective noise to 20
for i_iter in range(20)
loss,对应公式区域:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22'''
lama模型修改以后返回的结果,adv图像加了噪声
attack_res: adv掩码原始掩码
adv_hide_res: adv_hide掩码为E'(m)
adv_expd_res: adv_expd掩码为扩展
'''
attack_res = model(batch_adv)[predict_config.out_key][0]
adv_expd_res = model(batch_adv_expd)[predict_config.out_key][0]
adv_hide_res = model(batch_adv_hide)[predict_config.out_key][0]
with torch.no_grad():
ben_hide_res = model(batch_ben_hide)[predict_config.out_key][0]
# loss
loss_attack = mse_masked(attack_res, target, batch_adv['mask'])
loss_incp = mse_masked(adv_expd_res, target, batch_adv_expd['mask'])
loss_hide = mse_masked(adv_hide_res, ben_hide_res, batch_adv_hide['mask'])
print("iter", i_iter, ", attack loss: ", loss_attack.data, ", incp loss: ", loss_incp.data, ", hide loss: ", loss_hide.data)
loss = loss_attack + loss_incp + 2*loss_hide
loss.backward()
optimizer.step()
Writing

introduction的惯例,写总结,读文章可以先读这个部分和摘要,把这篇文章的地位和意义搞清楚,再去了解背景细节
Method要体现出和原始方法的对比
Question
为什么将noise训练的target设置为和原始图片颜色差异最大的纯色图片?
颜色差异最大是因为目标越极端,修改模型越依赖准确的梯度来进行优化,极端的颜色目标在颜色空间中与原始图片的距离最远,意味着要修改成原始图片的颜色的开销最大,为了将图片修改成这个目标颜色,修改模型需要在颜色空间中执行极大的变换,在这种极端目标下,噪声的扰动会显著干扰修改模型的梯度流,从而更难以找到有效的修改方向如何保证noise以纯色图片为target但是优化结果是肉眼不可见的图片?
限制noise在训练过程中的取值范围:
adv_noise.data = torch.clip(adv_noise.data, -0.025, 0.025)范围小就肉眼不可见
可以不用纯色,差异大就可以,使用纯色是因为好生成
